IBM ha lanzado a la comunidad de código abierto tres proyectos de inteligencia artificial (IA) diseñados para asumir el desafío de curar el cáncer. Se estima que el cáncer causó 9.6 millones de muertes en 2018, con un estimado de 18 millones de casos nuevos reportados en el mismo año. Los investigadores del grupo de Biología de Sistemas Computacionales de IBM en Zurich están trabajando en enfoques de IA y aprendizaje automático (ML) para «ayudar a acelerar nuestra comprensión de los principales impulsores y mecanismos moleculares de estas enfermedades complejas», así como métodos para mejorar nuestro conocimiento de la composición de tumores.
El primer proyecto, denominado PaccMann, que no debe confundirse con el popular juego de computadora Pac-Man, se describe como la «Predicción de la sensibilidad del compuesto anticancerígeno con redes neuronales multimodales basadas en la atención». IBM está trabajando en el algoritmo PaccMann para analizar automáticamente los compuestos químicos y predecir cuáles son los más propensos a combatir las cepas de cáncer, lo que podría acelerar este proceso. El algoritmo explota los datos sobre la expresión génica, así como las estructuras moleculares de los compuestos químicos. IBM dice que al identificar antes los posibles compuestos anticancerígenos puede reducir los costos asociados con el desarrollo de fármacos.
El segundo proyecto se llama «Influencia de la red de interacción de las representaciones vectoR de palabras», también conocido como INtERAcT. Esta herramienta es particularmente interesante dada su extracción automática de datos de valiosos artículos científicos relacionados con nuestra comprensión del cáncer. INtERAcT tiene como objetivo hacer que el lado académico de la investigación sea menos pesado mediante la extracción automática de información de estos documentos. En este momento, la herramienta se está probando para extraer datos relacionados con las interacciones proteína-proteína, un área de estudio que se ha marcado como una posible causa de la interrupción de los procesos biológicos en enfermedades como el cáncer.
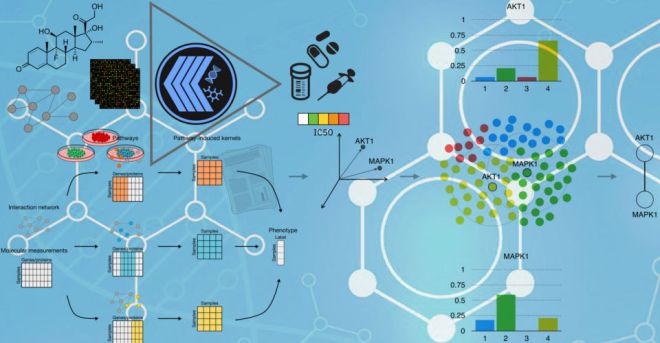
El tercer y último proyecto es el «aprendizaje de kernel múltiple inducido por la vía» o PIMKL. Este algoritmo utiliza conjuntos de datos que describen lo que sabemos actualmente sobre interacciones moleculares para predecir la progresión del cáncer y las posibles recaídas en los pacientes. PIMKL utiliza lo que se conoce como aprendizaje de múltiples núcleos para identificar vías moleculares cruciales para clasificar a los pacientes, brindando a los profesionales de la salud la oportunidad de individualizar y adaptar los planes de tratamiento.
El código de PaccMann e INtERAcT ha sido lanzado y está disponible en los sitios web de los proyectos. PIMKL se ha implementado en IBM Cloud y también se ha publicado el código fuente. Cada proyecto es de código abierto y ahora está disponible en el dominio público. IBM espera que al hacer que el código fuente esté disponible para otros investigadores y académicos, la comunidad científica pueda maximizar su impacto potencial.
IBM Gives Cancer-Killing Drug AI Project To the Open Source Community.